

Hugging Face has become the default platform for open-weight AI models in 2026. According to Hugging Face's model statistics blog (October 2025) and Hugging Face Hub docs, the Hub hosts over 2.2 million models and 2.2 billion downloads; the 50 most downloaded entities account for 80.22% of total Hub downloads—so a small set of models drives the majority of usage. TechAimag's top 10 Hugging Face models January 2026 and Hugging Face models sorted by downloads show sentence-transformers/all-MiniLM-L6-v2 among the most downloaded, with small models dominating: 92.48% of downloads are for models with fewer than 1 billion parameters, 86.33% for under 500M, and 69.83% for under 200M. NLP leads at 58.1%, computer vision at 21.2%, and audio at 15.1%. Python is the tool many teams use to visualize Hub stats and modality data for reports like this one. This article examines where Hugging Face stands in 2026, why small models and NLP lead, and how Python powers the charts that tell the story.
2M+ Models, 80% of Downloads From the Top 50
The concentration of downloads on a small set of models is striking. Hugging Face's model statistics report that the 50 most downloaded entities on the Hub account for 80.22% of total Hub downloads—so long-tail models exist by the millions, but production usage clusters around embeddings, sentence transformers, and popular base models. The Hub hosts over 2.2 million models (over 2.28 million as of 2025 in some counts), with download stats tracked per model and version. The following chart, generated with Python and matplotlib using Hugging Face–style data, illustrates download share by modality (NLP, computer vision, audio, multimodality, time series) in 2025–2026.
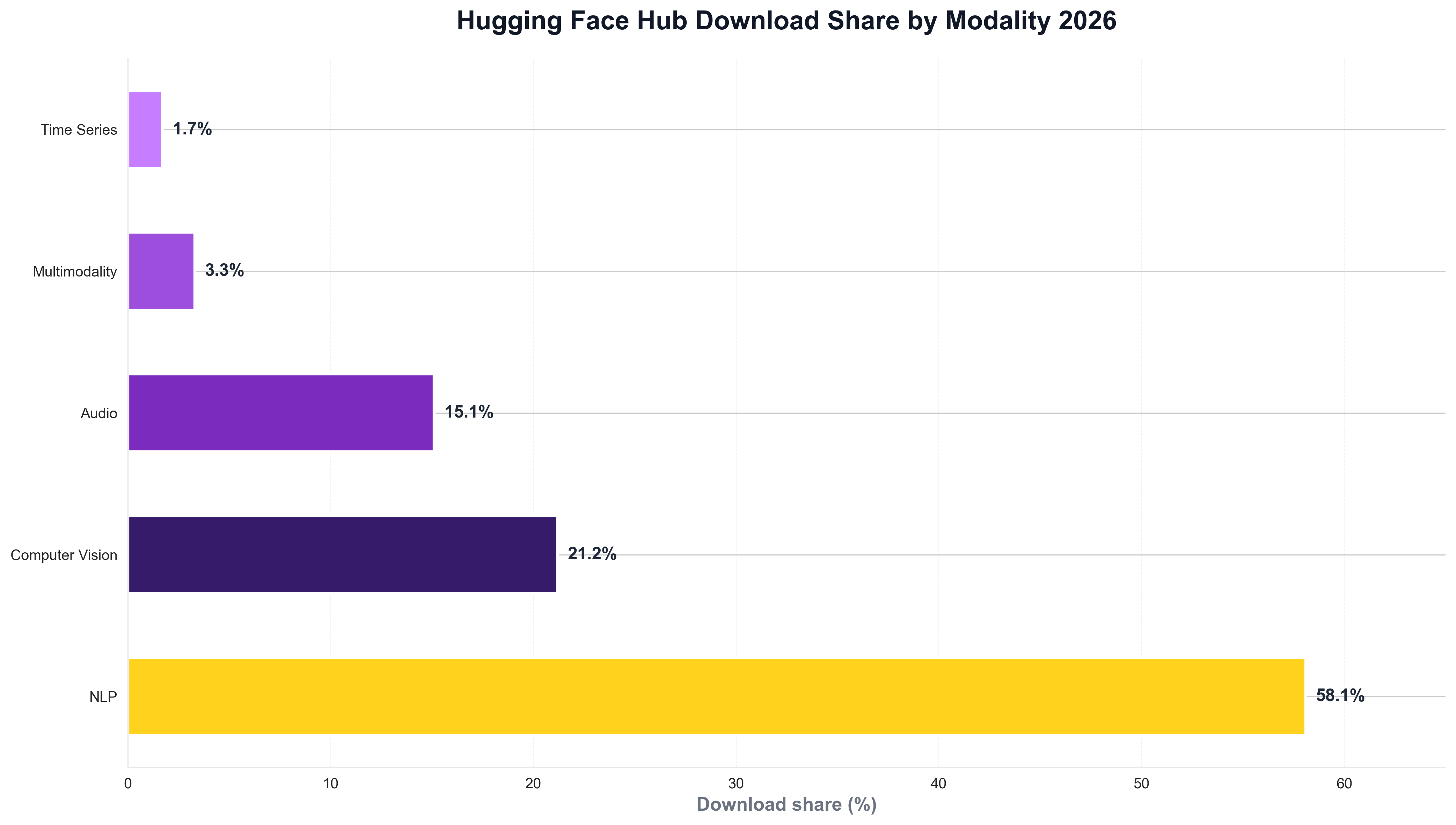
The chart above shows NLP at 58.1%, computer vision at 21.2%, audio at 15.1%—reflecting the dominance of text and vision use cases on the Hub. Python is the natural choice for building such visualizations: ML and data teams routinely use Python scripts to load Hub or survey data and produce publication-ready charts for reports and articles like this one.
92% of Downloads Are for Models Under 1B Parameters
Small models dominate actual usage on the Hub. Hugging Face's model statistics report 92.48% of downloads for models with fewer than 1 billion parameters, 86.33% for under 500 million, and 69.83% for under 200 million—so despite hype around large language models, open-weight adoption is driven by embeddings, sentence transformers, and smaller models that fit edge and cost constraints. Within NLP, text encoders represent over 45% of total downloads, compared to 9.5% for decoders and 3% for encoder-decoders. When teams need to visualize model-size or modality trends, they often use Python and matplotlib or seaborn. The following chart, produced with Python, summarizes download share by model size (<200M, <500M, <1B, 1B+) in a style consistent with the Hub blog.
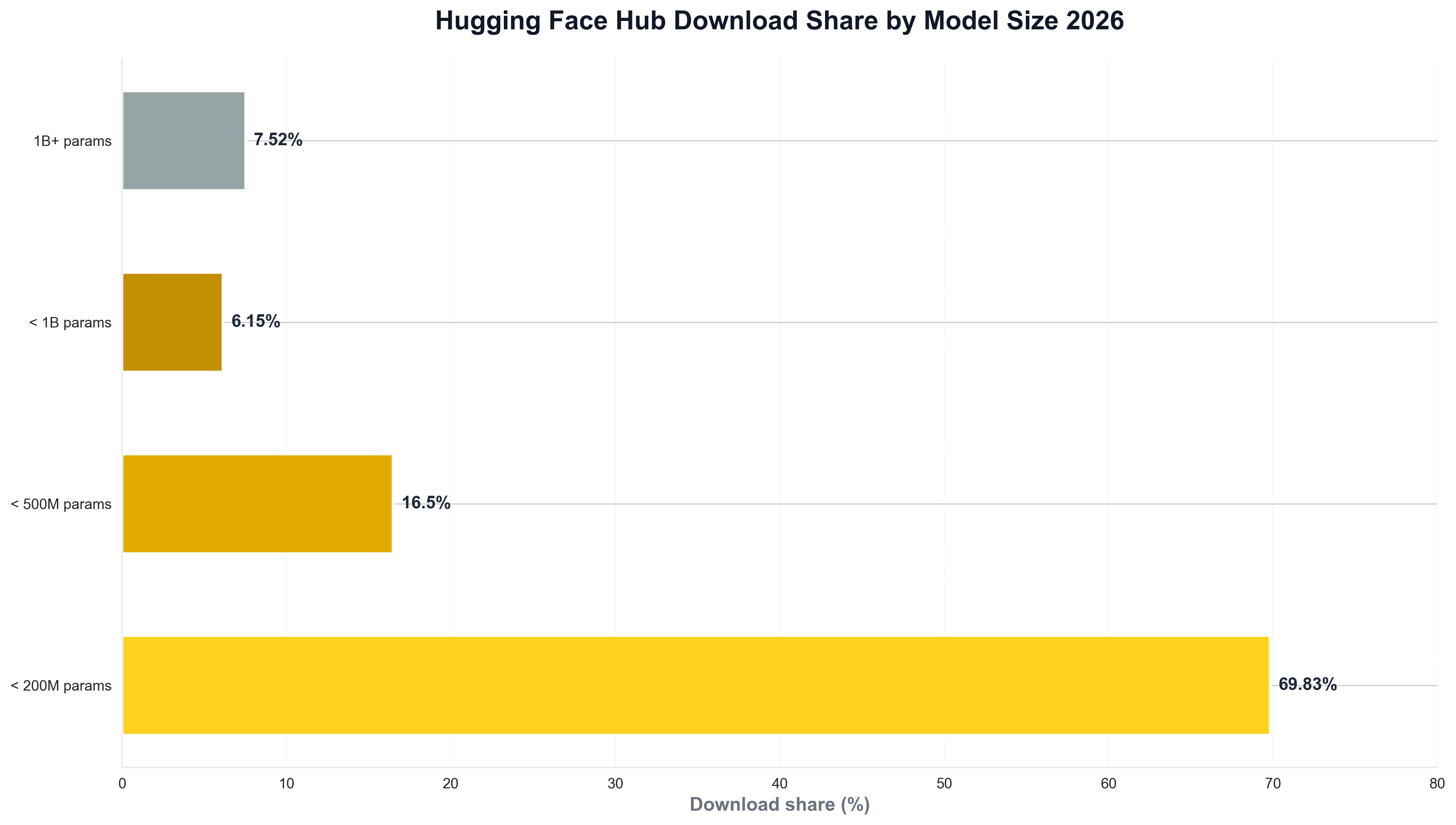
The chart illustrates small models capturing the vast majority of downloads—context that explains why Hugging Face is as much about embeddings and small models as it is about LLMs. Python is again the tool of choice for generating such charts from Hub or internal data, keeping analytics consistent with the rest of the data stack.
NLP 58%, CV 21%, Audio 15%: Why Modality Matters
The modality mix on the Hub reflects production demand. Hugging Face's model statistics report NLP at 58.1%, computer vision at 21.2%, audio at 15.1%, multimodality at 3.3%, and time series at 1.7%—so text and vision drive the bulk of downloads, with audio growing. For teams that track Hub adoption or modality trends over time, Python is often used to load download or survey data and plot distributions. A minimal example might look like the following: load a CSV of download share by modality, and save a chart for internal or public reporting.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("hf_modality_downloads.csv")
fig, ax = plt.subplots(figsize=(10, 5))
ax.bar(df["modality"], df["pct"], color=["#ffd21e", "#371b6b", "#7b2cbf", "#9d4edd", "#c77dff"])
ax.set_ylabel("Download share (%)")
ax.set_title("Hugging Face Hub downloads by modality")
fig.savefig("public/images/blog/hf-modality-trend.png", dpi=150, bbox_inches="tight")
plt.close()
That kind of Python script is typical for ML platform and developer relations teams: same language as the transformers and datasets libraries, and direct control over chart layout and messaging.
Top Models, Embeddings, and the Long Tail
The top of the leaderboard is dominated by embeddings and sentence transformers. Hugging Face models by downloads and TechAimag's January 2026 top 10 highlight sentence-transformers/all-MiniLM-L6-v2 and similar models with tens of millions of downloads—used for semantic search, RAG, and embeddings in production. The Top Contributors: Model Downloads page shows individual and organizational leaders; the long tail of 2M+ models includes fine-tunes, experiments, and niche use cases. Python is the language many use to analyze Hub stats and visualize adoption for reports like this one.
Conclusion: Hugging Face as the Open-Weight Default in 2026
In 2026, Hugging Face Hub is the default for open-weight AI: over 2.2 million models, 2.2 billion downloads, and 80.22% of downloads from the top 50 entities. 92.48% of downloads are for models under 1B parameters; NLP leads at 58.1%, computer vision at 21.2%, audio at 15.1%. Python remains the language that powers the analytics—Hub stats, modality and size distributions, and the visualizations that explain the story—so that for Google News and Google Discover, the story in 2026 is clear: Hugging Face is where open-weight AI lives, and Python is how many of us chart it.




