

Retrieval-Augmented Generation (RAG) has become the backbone of enterprise generative AI in 2026. According to DataNucleus's RAG and enterprise GenAI guide, 71% of organizations report regular use of generative AI in at least one business function—up from 65% in early 2024—and 78% use AI of any kind in at least one function. At the same time, only 17% attribute 5% or more of earnings to GenAI so far, underscoring the need for grounded, dependable solutions like RAG over experimental approaches. Databricks' State of AI: Enterprise Adoption & Growth Trends reports that vector databases supporting RAG applications grew 377% year-over-year, and ISG's State of Enterprise AI Adoption 2025 notes that 31% of prioritized AI use cases reached full production in 2025—double the 2024 rate. The story in 2026 is that RAG is the default for enterprise knowledge and GenAI—and Python is the language most teams use to build and visualize RAG adoption and impact. This article examines why RAG became the backbone, how Python fits the stack, and how Python powers the charts that tell the story.
RAG as the Backbone of Enterprise GenAI
RAG did not become the default overnight. DataNucleus's RAG demystified guide and IBM's RAG architecture explain that RAG connects large language models to enterprise knowledge—policies, contracts, manuals, tickets—in real time by retrieving evidence from approved sources before generating answers. That "open book" approach leaves the model intact while updating data, distinguishing it from fine-tuning. DataNucleus states that 71% of organizations report regular GenAI use in at least one function and 78% use AI of any kind—but only 17% attribute 5% or more of earnings to GenAI, so the gap between experimentation and value delivery is still wide. The following chart, generated with Python and matplotlib using DataNucleus and ISG–style data, illustrates GenAI and RAG adoption in 2025–2026.
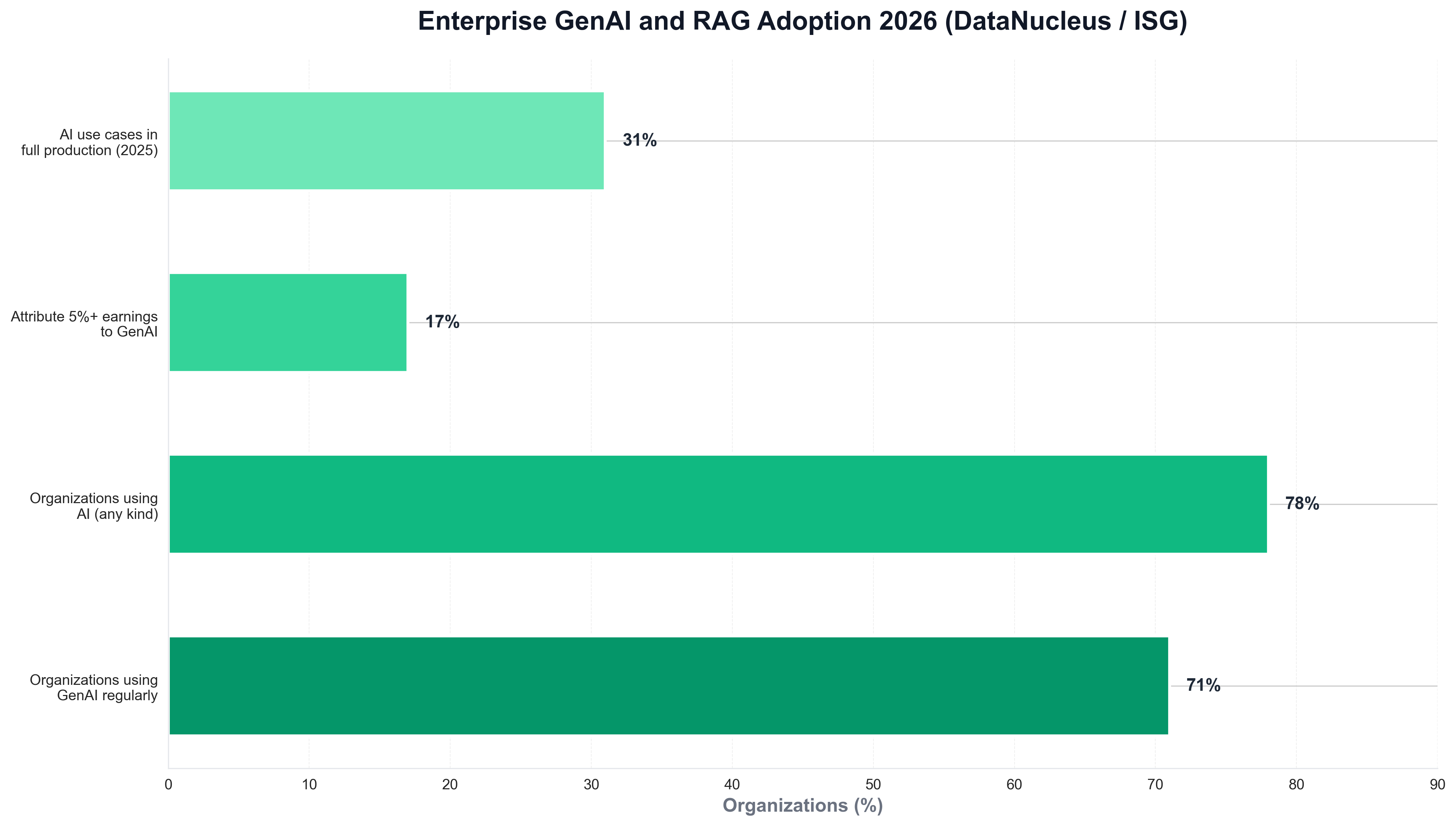
The chart above shows 71% using GenAI regularly, 78% using AI in at least one function, and 17% attributing 5%+ earnings to GenAI—reflecting the shift to RAG as the grounded path to value. Python is the natural choice for building such visualizations: data and product teams routinely use Python scripts to load survey or internal usage data and produce publication-ready charts for reports and articles like this one.
377% Year-over-Year Growth in Vector Databases Supporting RAG
The infrastructure behind RAG is scaling fast. Databricks' State of AI: Enterprise Adoption & Growth Trends reports that vector databases supporting RAG applications grew 377% year-over-year—and organizations deployed 11 times more AI models into production compared to the prior year, with 210% more organizations registering models for production use. ISG's State of Enterprise AI Adoption 2025 adds that 31% of prioritized AI use cases reached full production in 2025, double the 2024 rate. When teams need to visualize RAG adoption by use case—HR policy assistants, IT help desk, legal and finance copilots, operations—they often use Python and matplotlib or seaborn. The following chart, produced with Python, summarizes the leading enterprise RAG use cases as reported in DataNucleus and practitioner guides.
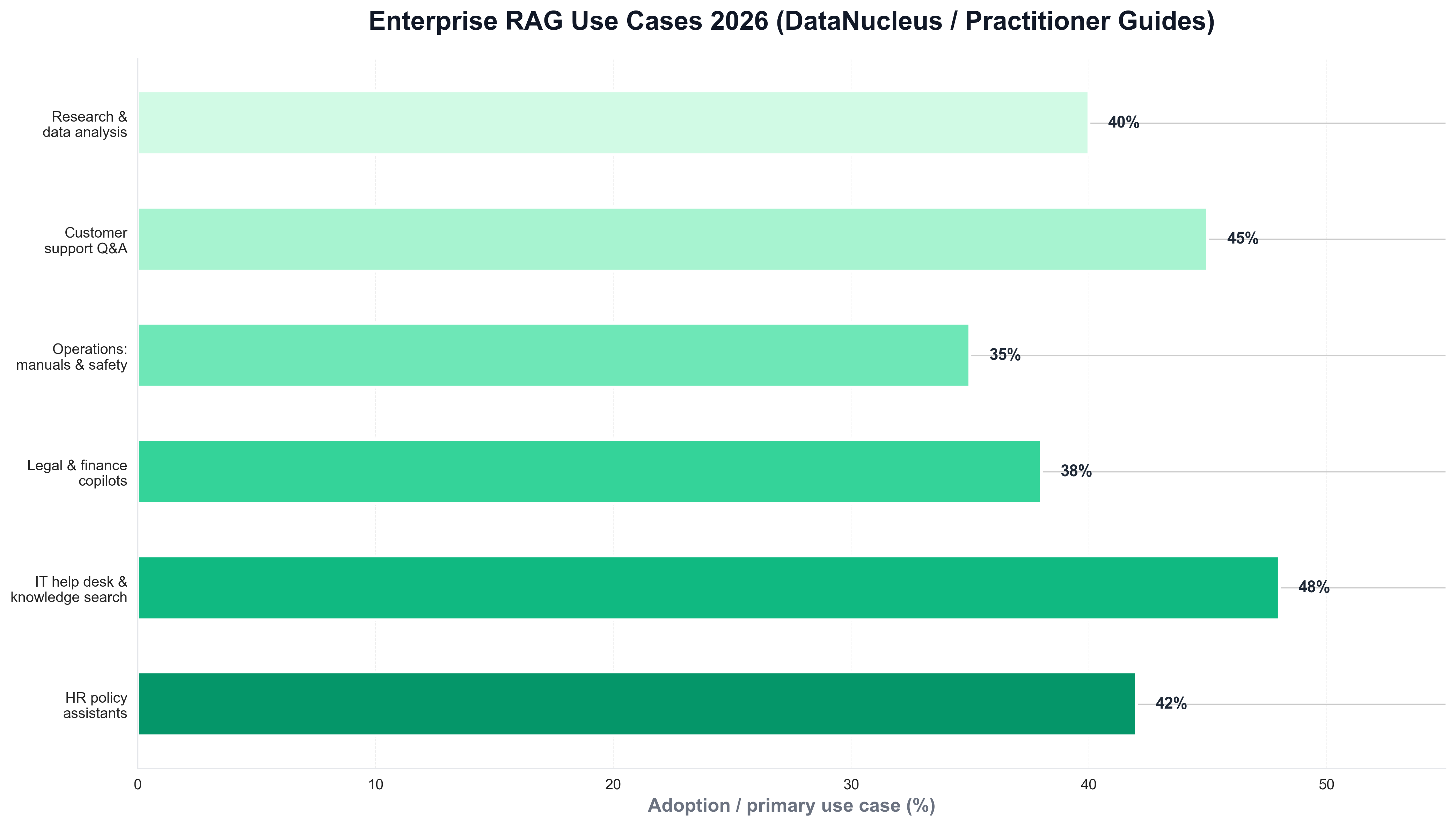
The chart illustrates HR policy assistants, IT help desk, legal and finance copilots, and operations teams searching manuals and safety documents—context that explains why RAG is the backbone of enterprise GenAI. Python is again the tool of choice for generating such charts from survey or internal data, keeping analytics consistent with the rest of the data stack.
Why RAG Won: Grounded Answers and Enterprise Knowledge
The business case for RAG is grounded answers. DataNucleus and Applied AI's Enterprise RAG Architecture stress that RAG retrieves relevant documents from trusted stores—policies, contracts, manuals, tickets—then generates answers grounded in that evidence, with source citations. That reduces hallucination and compliance risk compared to raw LLM output. The typical pipeline involves ingesting and indexing documents, retrieving top candidates using semantic or hybrid search, re-ranking results, and generating answers with source citations. For teams that track RAG adoption or use case mix over time, Python is often used to load survey or telemetry data and plot trends. A minimal example might look like the following: load a CSV of RAG use cases by department, and save a chart for internal or public reporting.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("rag_use_cases_survey.csv")
fig, ax = plt.subplots(figsize=(10, 6))
ax.barh(df["use_case"], df["adoption_pct"], color="#059669", edgecolor="white", height=0.6)
ax.set_xlabel("Adoption (%)")
ax.set_title("Enterprise RAG Use Cases 2026 (survey-style)")
fig.savefig("public/images/blog/rag-use-cases-trend.png", dpi=150, bbox_inches="tight")
plt.close()
That kind of Python script is typical for product and strategy teams: same language as much of their RAG tooling (LangChain, LlamaIndex), and direct control over chart layout and messaging.
From Simple RAG to Production: Hybrid Search and Reranking
Simple RAG rarely survives production. Applied AI's Enterprise RAG Architecture and DataNucleus explain that modern RAG systems incorporate hybrid search (BM25 + dense retrieval) that often outperforms pure semantic approaches, cross-encoder reranking to improve precision, and query transformation (HyDE, multi-query, decomposition) to address query-document mismatch. Python is the default language for RAG pipelines: LangChain, LlamaIndex, Haystack, and Chroma are Python-first, and vector stores (Pinecone, Weaviate, Qdrant, pgvector) are typically accessed from Python. When teams visualize retrieval quality, latency, or adoption by use case, they typically use Python and pandas, matplotlib, or seaborn—the same stack they use for data pipelines and evaluation.
Vector Databases and Python: The Standard Stack
The RAG stack is Python + vector DB + LLM. DataNucleus and Applied AI note that the vector database market has stratified by dataset size and latency: PostgreSQL with pgvector handles many production workloads for under 5 million vectors with 100–200 ms acceptable latency; purpose-built databases (Pinecone, Weaviate, Qdrant, Milvus) are used for 10M+ vectors or sub-50 ms latency. Python is the glue: LangChain and LlamaIndex orchestrate retrieval, reranking, and generation; Python clients connect to vector stores and LLM APIs; and Python scripts evaluate and visualize RAG quality and adoption. So the story is not just "RAG won"; it is Python as the language of RAG engineering and analytics, from building pipelines to measuring their impact.
What the 71% and 17% Figures Mean for Strategy
The 71% GenAI use and 17% earnings attribution figures have practical implications. DataNucleus and ISG both stress that enterprises are rapidly moving from pilots to production but most are still underdelivering on cost-cutting and productivity expectations—so grounded, dependable solutions like RAG are preferred over experimental approaches. For product and engineering, the takeaway is that RAG is the default for enterprise knowledge and GenAI—new projects should assume retrieval-augmented workflows where answers must be grounded and citable. For data and strategy, the takeaway is that 377% vector DB growth and 31% use cases in full production (2x 2024) show momentum—but 17% earnings attribution means value delivery is still the priority. For reporting, Python remains the language of choice for pulling survey data and visualizing RAG adoption—so the same Python scripts that power internal dashboards can power articles and public reports.
Conclusion: RAG as the New Normal for Enterprise GenAI
In 2026, RAG is the backbone of enterprise generative AI: 71% of organizations use GenAI in at least one function, 78% use AI of any kind, and vector databases supporting RAG grew 377% year-over-year. Only 17% attribute 5%+ earnings to GenAI so far—underscoring the need for grounded solutions like RAG over experiments. 31% of prioritized AI use cases reached full production in 2025 (double 2024), and HR policy assistants, IT help desk, legal and finance copilots, and operations teams are the leading use cases. Python is central to this story: the language of LangChain, LlamaIndex, and RAG pipelines, and the language of visualization for adoption and impact. Teams that treat RAG as the default for enterprise knowledge—and use Python to build and measure it—are well positioned for 2026 and beyond: RAG is where enterprise GenAI lives; Python is where the story gets told.




