

Redis has become the default for high-performance caching and key-value data in 2026. According to Redis's Digital Transformation Index report and Redis's 4 key findings from the DTI survey, 78% of respondents are either currently using caching or plan to do so soon—and 52% of organizations use key-value databases, nearly on par with relational databases at 55%. Redis's Digital Transformation Is Accelerating blog adds that 52% of respondents stated they cannot afford any downtime in either database or cache, highlighting the critical role of highly available data layers. Redis Enterprise survey results report that nearly 80% of Redis Enterprise customers plan to increase their usage of Redis, and Redis's How Redis is Used in Practice notes that 70% of Redis users employ it for message queues, primary datastore, or high-speed data ingest—not just caching. The story in 2026 is that Redis is the default for caching, session store, and real-time data—and Python is the language many teams use to connect, script, and visualize adoption and performance. This article examines why 78% use or plan caching, how Redis fits the stack, and how Python powers the charts that tell the story.
78% Use or Plan Caching: Caching as a Strategic Layer
Redis's lead in caching did not happen overnight. Redis's 4 key findings from the DTI survey and Redis's Digital Transformation Index report that 78% of respondents are either currently using caching or plan to do so soon—caching has moved beyond performance optimization to become a critical, strategic component of modern applications that need to scale. 52% of organizations use key-value databases compared to 55% using relational databases—so key-value and relational adoption are nearly on par. The following chart, generated with Python and matplotlib using Redis DTI–style data, illustrates caching and key-value adoption in 2025–2026.
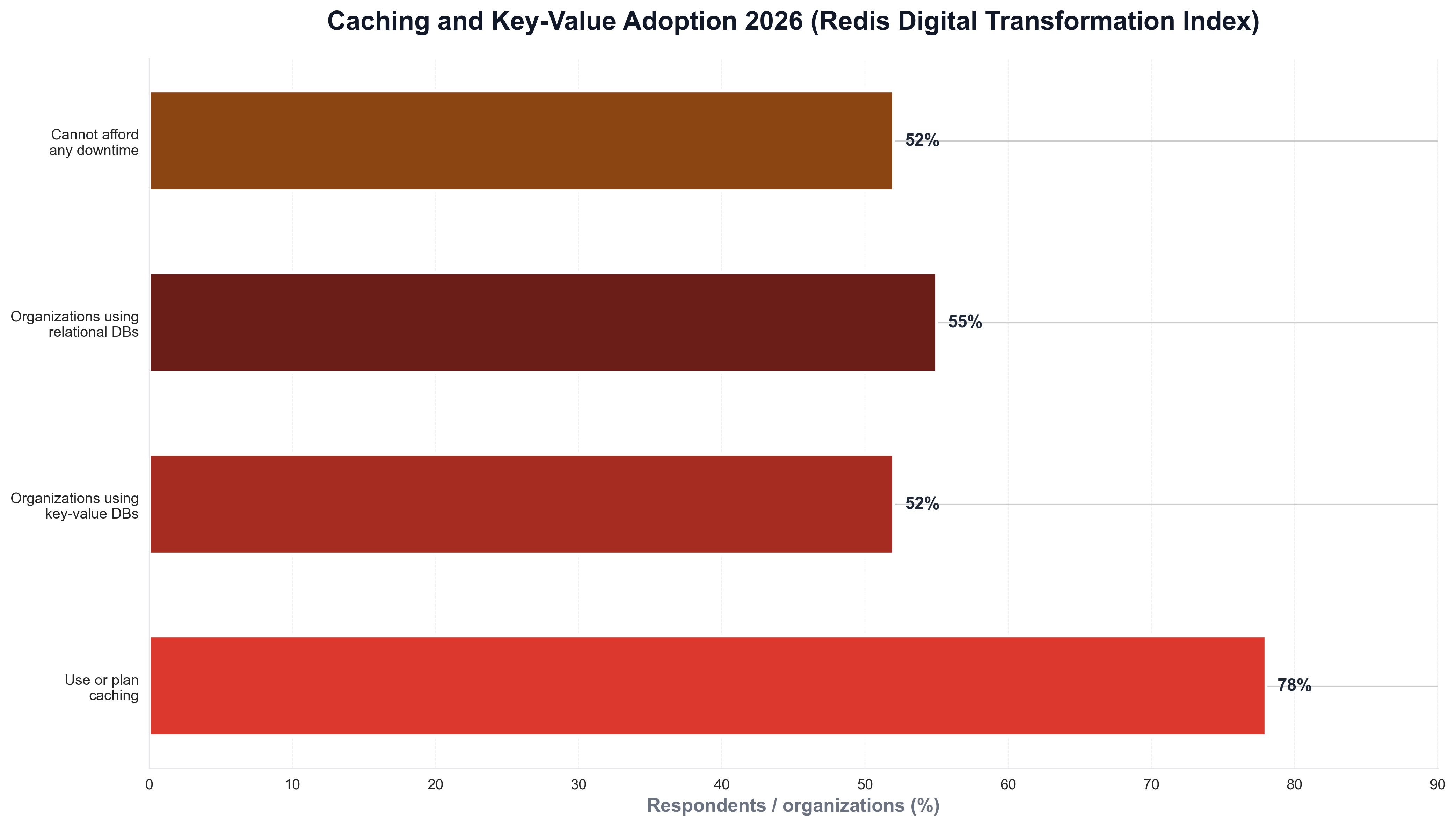
The chart above shows 78% using or planning caching, 52% using key-value databases, 55% using relational, and 52% unable to afford any downtime—reflecting Redis's role as the default for high-performance data. Python is the natural choice for building such visualizations: platform and data teams routinely use Python scripts to load survey or internal usage data and produce publication-ready charts for reports and articles like this one.
80% Plan to Increase Redis Usage: Beyond Caching
The commitment to Redis is growing. Redis Enterprise survey results report that nearly 80% of Redis Enterprise customers plan to increase their usage of Redis to serve growing business needs—and Redis's How Redis is Used in Practice notes that 70% of Redis users employ it for message queues, primary datastore, or high-speed data ingest, not just caching. When teams need to visualize Redis use cases—caching, session store, message queue, primary DB, ingest—they often use Python and matplotlib or seaborn. The following chart, produced with Python, summarizes Redis use cases as reported in Redis surveys and blogs.
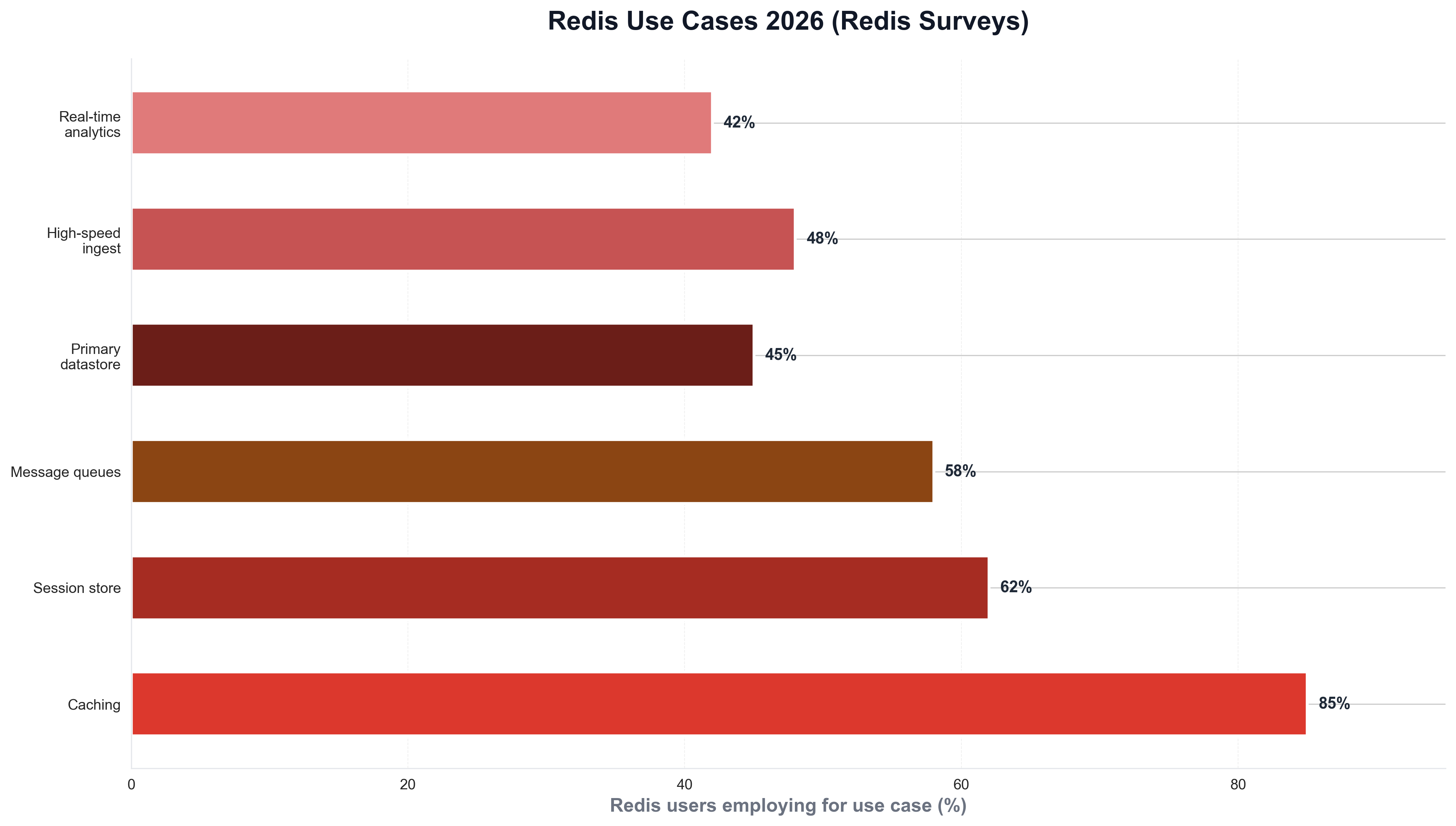
The chart illustrates caching, session store, message queues, primary datastore, and high-speed ingest—context that explains why 80% plan to increase usage. Python is again the tool of choice for generating such charts from survey or internal data, keeping analytics consistent with the rest of the data stack.
Why Redis Won: Speed, Versatility, and Python
The business case for Redis is speed, versatility, and ecosystem. Redis's DTI findings and Redis's Digital Transformation Is Accelerating stress that organizations adopting modern data layers with NoSQL (including Redis) experience significantly higher digital transformation maturity; 52% cannot afford any downtime in database or cache—so high availability and performance are non-negotiable. Python is the default language for connecting to Redis (redis-py, aioredis), building workers and pipelines, and visualizing hit rates, latency, and adoption. For teams that track caching adoption or use case mix over time, Python is often used to load survey or telemetry data and plot trends. A minimal example might look like the following: load a CSV of Redis use cases by team, and save a chart for internal or public reporting.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("redis_use_cases_survey.csv")
fig, ax = plt.subplots(figsize=(10, 6))
ax.barh(df["use_case"], df["adoption_pct"], color="#dc382d", edgecolor="white", height=0.6)
ax.set_xlabel("Adoption (%)")
ax.set_title("Redis use cases 2026 (survey-style)")
fig.savefig("public/images/blog/redis-use-cases-trend.png", dpi=150, bbox_inches="tight")
plt.close()
That kind of Python script is typical for platform and data teams: same language as much of their Redis tooling, and direct control over chart layout and messaging.
52% Cannot Afford Any Downtime: High Availability as Table Stakes
52% of respondents stated they cannot afford any downtime in either database or cache—so high availability and resilience are table stakes. Redis's DTI survey and Redis's caching assessment emphasize that caching has become critical infrastructure; Redis Enterprise and Redis Cluster provide replication, failover, and multi-AZ options for production. Python fits into this story as the language of monitoring and visualization—many teams use Python scripts to query Redis INFO, aggregate metrics, and plot latency and availability with matplotlib or seaborn.
Redis 2026 Predictions: AI and Context Engines
Redis's 2026 predictions emphasize AI integration—context engines becoming critical for AI applications rather than compute power alone—and Redis is positioning itself as essential for AI-powered applications requiring sophisticated data context (sessions, embeddings, real-time state). Python is the language of choice for AI/ML pipelines that consume Redis—vector search, session state, rate limiting—so from caching to AI context, Python and Redis form a standard stack.
What the 78% Figure Means for Developers and Teams
The 78% "use or plan caching" figure has practical implications. Redis's Digital Transformation Index and Redis's 4 key findings are based on Redis's inaugural DTI survey. For new projects, the takeaway is that caching (and often Redis) is the default for session store, rate limiting, and real-time data—unless the stack standardizes on Memcached or another store. For hiring and training, Redis and caching are core skills for backend and platform roles. For reporting, Python remains the language of choice for pulling survey or metrics data and visualizing caching adoption—so the same Python scripts that power internal dashboards can power articles and public reports.
Conclusion: Redis as the Default for Caching and Real-Time Data
In 2026, Redis has become the default for high-performance caching and key-value data: 78% of respondents use or plan caching, 52% of organizations use key-value databases (nearly on par with relational at 55%), and 52% cannot afford any downtime in database or cache. 80% of Redis Enterprise customers plan to increase usage, and 70% use Redis for message queues, primary datastore, or high-speed ingest—not just caching. Python is central to this story: the language of connection (redis-py), workers and pipelines, and visualization for adoption and performance. Teams that treat Redis as the default for caching and real-time data—and use Python to build and measure—are well positioned for 2026 and beyond: Redis is where high-performance data lives; Python is where the story gets told.



